|
Assistant Professor at Mayo Clinic (Department of AI & Informatics). I work on medical image analysis and machine learning. My research focuses on computational pathology, with particular emphasis on visual search in histopathology, multimodal agentic and generative AI for pathology image analysis, visual generative models, and reinforcement learning to emulate pathologist diagnostic workflows, alongside methodological advances in supervised, self-supervised, semi/weakly supervised learning, diffusion models, and reinforcement learning. Email / CV / Bio / Google Scholar / LinkedIn / Github / Youtube |

|
|
|

|
Saghir Alfasly, Wataru Uegami, MD Enamul Hoq, Ghazal Alabtah H.R. Tizhoosh, NeurIPS , 2025 [Project webpage] [Video] [Paper] [Supplementary] [Code] The study introduces HeteroTissue-Diffuse, a latent diffusion framework for synthesizing histopathology images that maintain tissue heterogeneity and fine morphological detail. Unlike conventional generative approaches that yield homogeneous samples, this method employs a novel conditioning mechanism and scales to both annotated and unannotated datasets, enabling the creation of realistic, diverse, and annotated synthetic tissue slides. |
|
|
Saghir Alfasly, Abubakr Shafique, Peyman Nejat, Jibran Khan Areej Alsaafin, Ghazal Alabtah, H.R.Tizhoosh, CVPR, 2024 [Project webpage] [Demo] [Paper] [Supplementary] [Code] [Data] In this work, we introduce a fast patch selection method (FPS) for efficient selection of representative patches while preserving spatial distribution. HistoRotate, is a 360∘ rotation augmentation for training histopathology models, enhancing learning without compromising contextual information. PathDino, is a compact histopathology Transformer with five small vision transformer blocks and ≈9 million parameters. |
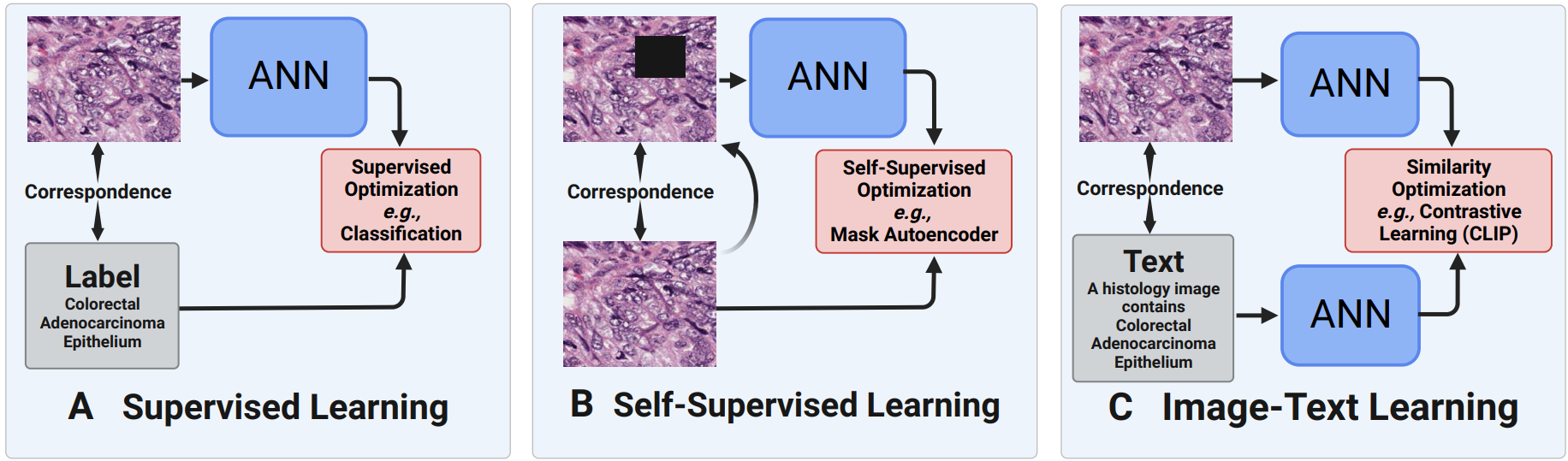
|
Saghir Alfasly, Peyman Nejat, Sobhan Hemati, Jibran Khan, Isaiah Lahr, Areej Alsaafin, Abubakr Shafique, Nneka Comfere, Dennis Murphree, Chady Meroueh, Saba Yasir, Aaron Mangold, Lisa Boardman, Vijay H. Shah, Joaquin J. Garcia, H.R. Tizhoosh, Mayo Clinic Proceedings: Digital Health, 2024 [Paper] [Supplementary] This paper investigates the efficacy of the foundation models in the domain of histopathology by conducting a detailed comparison between these models, specifically CLIP derivatives (PLIP and BiomedCLIP), and traditional, domain-specific histology models that leverage well-curated datasets. Through a rigorous evaluation process on eight diverse datasets, including four internal from Mayo Clinic and four well-known public datasets (PANDA, BRACS, CAMELYON16, DigestPath). The findings show that domain-specific models, such as DinoSSLPath and KimiaNet, provide better performance across various metrics, underlining the significance of clean large datasets for histopathological analyses. |

|
Abubakr Shafique, Saghir Alfasly, Areej Alsaafin, Peyman Nejat, Jibran Khan H.R.Tizhoosh, Preprint, 2023 [Paper] [Supplementary] We propose SDM, a novel method for selecting diverse WSI patches, minimizing patch count while capturing all morphological variations. SDM outperforms the state-of-the-art, achieving high representativeness without needing parameter tuning. |
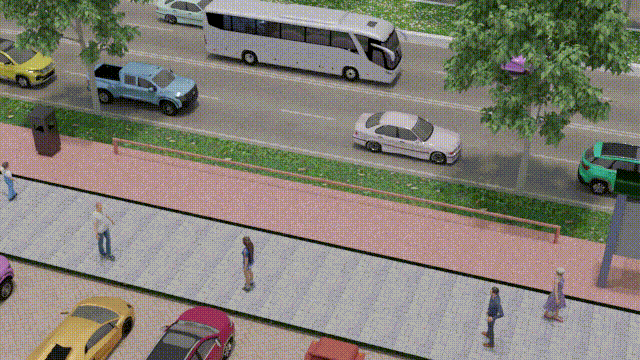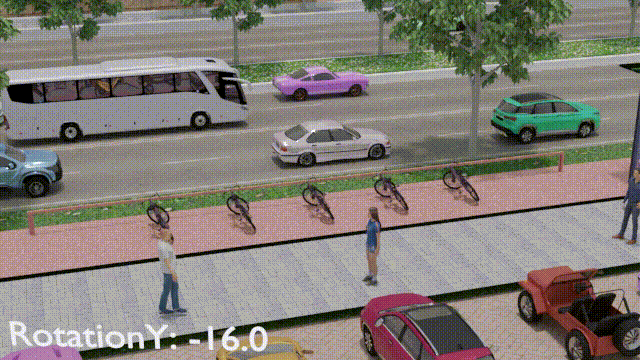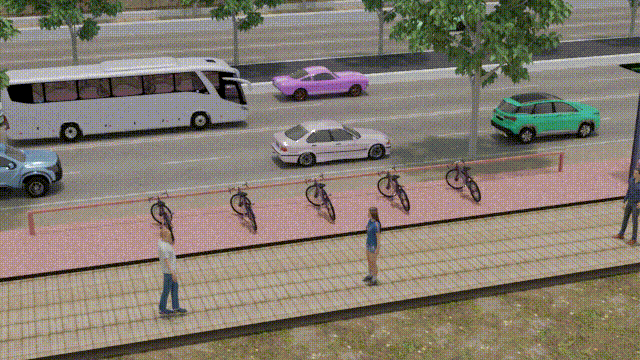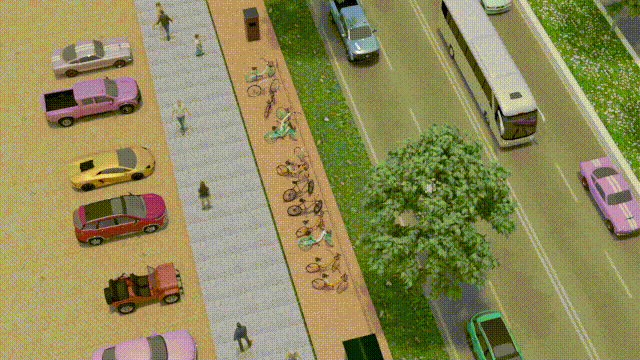
|
Saghir Alfasly, Zaid Al-Huda, Saifullahi Bello, Ahmed Elazab Jian Lu, Chen Xu, IEEE Transactions on Intelligent Transportation Systems, 2023 [Project webpage] [Video] [Paper] [Supplementary] [Code] [Data] We leveraged the power of 3D graphics and computer vision techniques to tackle a real-world problem, that we propose object-to-spot rotation estimation which is of particular significance for intelligent surveillance systems, bike-sharing systems, and smart cities. We introduced a rotation estimator (OSRE) that estimates a parked bike rotation with respect to its parking area. |
|
|
Saghir Alfasly, Charles K. Chui, Qingtang Jiang, Jian Lu, Chen Xu, IEEE Transactions on Neural Networks and Learning Systems, 2022 [Video] [Paper] We propose a new spatiotemporal attention scheme, termed synchronized spatiotemporal and spatial attention (SSTSA), which derives the spatiotemporal features with temporal and spatial multiheaded self-attention (MSA) modules. |
|
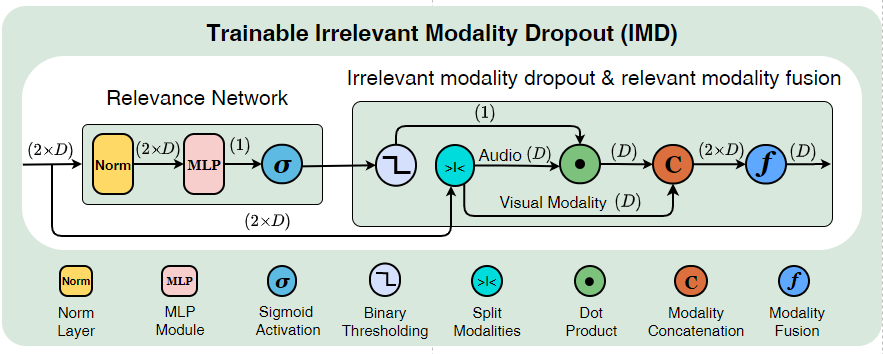
Saghir Alfasly, Jian Lu, Chen Xu, Yuru Zou, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [Paper] [Supp] Multimodal learning for video understanding (Text, Audio, RGB, Motion). We present a multimodal learning approach that leverage several modalities and several on-the-shelf models for both audio and language understanding. We proposed Irrelevant Modality Dropout (IMD) that drops the irrelevant audio from further processing while fusing the relevant audio-visual data for better video understanding. |
|
|
Saghir Alfasly, Jian Lu, Chen Xu, Zaid Al-Hudad Qingtang Jiang, ZhaosongLu , Charles K. Chui, Neurocomputing, 2022 [Video] [Paper] This research study addresses the following question: To what extent can a fast independent adaptive algorithm select the most discriminative and representative frames to downsize huge video datasets while improving action recognition performance? |
|
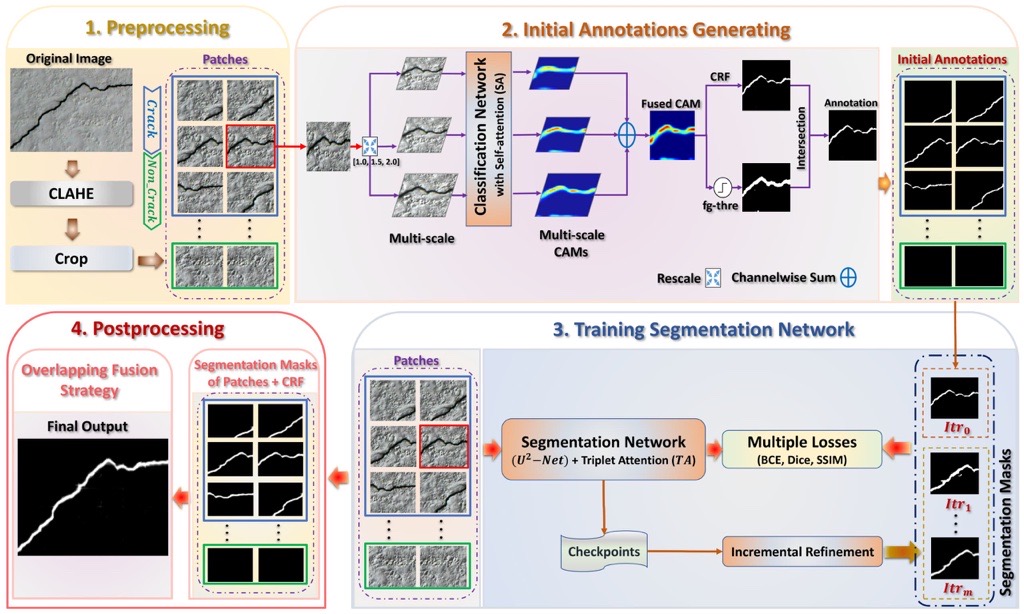
Zaid Al-Hudad Bo Peng Riyadh Nazar Ali Algburi, Saghir Alfasly, Tianrui Li , Applied Intelligence, 2022 [Paper] Weakly supervised pavement crack semantic segmentation based on multi-scale object localization and incremental annotation refinement. |
|
|
Saghir Alfasly, Yongjian Hu, Haoliang Li, Tiancai Liang, Xiaofeng Jin, BeiBei Liu, Qingli Zhao, IEEE Access, 2019 [Paper] [Video] We propose a multi-label similarity learning framework for vehicle re-identification. |
|
Saghir Alfasly, Yongjian Hu, Tiancai Liang, Xiaofeng Jin, Qingli Zhao, Beibei Liu, IEEE International Conference on Image Processing, 2019 [Paper] [Github] We propose variational Representation Learning for object Re-Identification. The proposed method has been evaluated on vehicle re-identification and person re-identification and face recognition. |
|
|
Saghir Alfasly, BeiBei Liu, Yongjian Hu, Yufei Wang, Chang-Tsun Li, IEEE Access, 2019 [Paper] [Github] [Video] For small objects detection like pedestrians in the outdoor surveillance, we propose a fast, lightweight, and auto-zooming-based framework for small pedestrian detection. |
Source: jonbarron/website